Storage Engine
Introduction
The storage engine is responsible for storing the data of the database. Mito, based on LSMT (Log-structured Merge-tree), is the storage engine we use by default. We have made significant optimizations for handling time-series data scenarios, so mito engine is not suitable for general purposes.
Architecture
The picture below shows the architecture and process procedure of the storage engine.
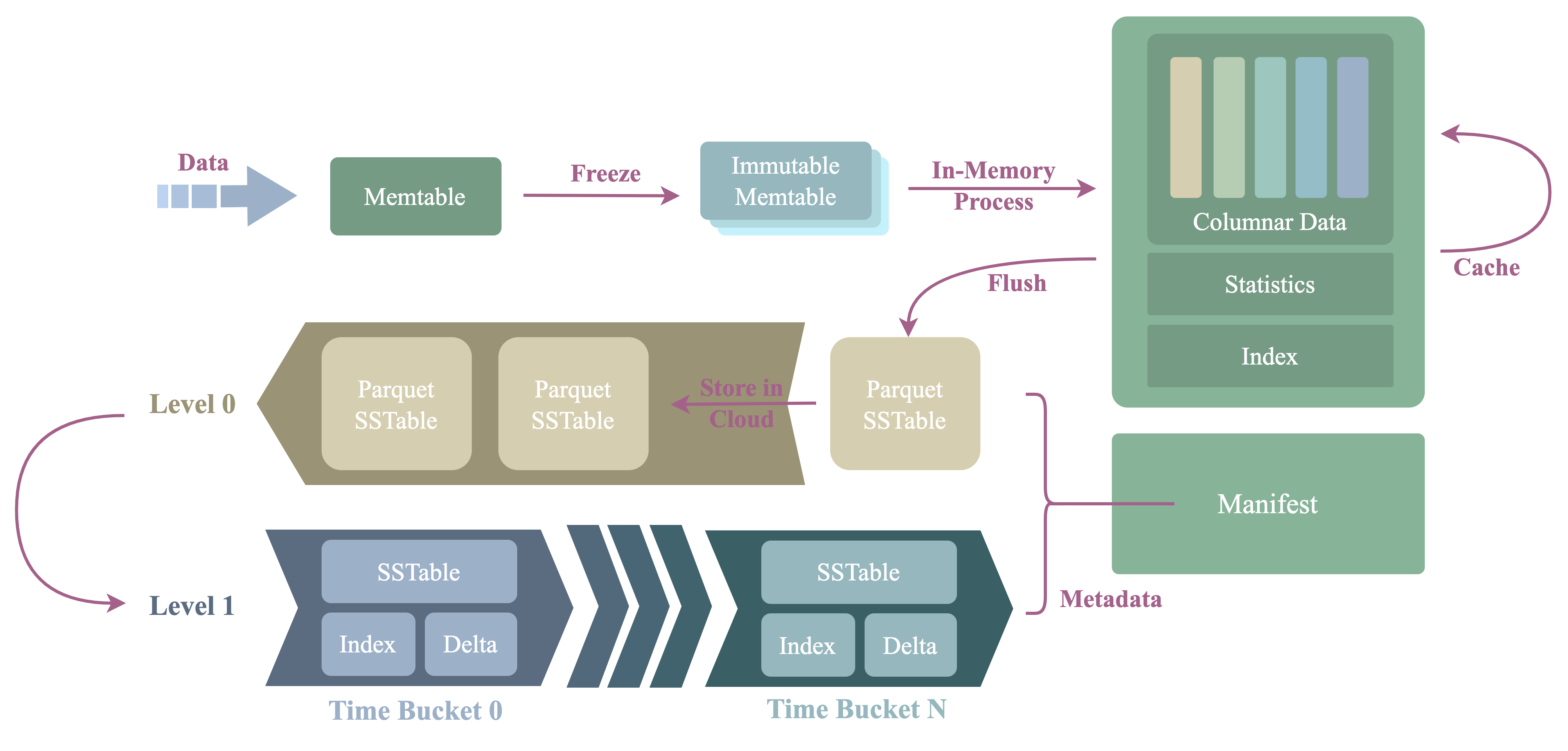
The architecture is the same as a traditional LSMT engine:
- WAL
- Guarantees high durability for data that is not yet being flushed.
- Based on the
Log StoreAPI, thus it doesn't care about the underlying storage media. - Log records of the WAL can be stored on the local disk, or in a remote log service such as
Kafka (remote WAL) that implements the
Log StoreAPI.
- Memtables:
- Data is written into the
active memtable, akamutable memtablefirst. - When a
mutable memtableis full, it will be changed to aread-only memtable, akaimmutable memtable.
- Data is written into the
- SST
- The full name of SST, aka SSTable is
Sorted String Table. Immutable memtableis flushed to persistent storage and produces an SST file.- Rows in an SST are sorted by primary key and time index; see Data Layout in SST Files.
- The full name of SST, aka SSTable is
- Compactor
- Small
SSTis merged into largeSSTby the compactor via compaction. - The default compaction strategy is TWCS. Compaction groups SST files into time windows and, together with TTL, removes expired data. See Compaction.
- Small
- Manifest
- The manifest stores the metadata of the engine, such as the metadata of the
SST.
- The manifest stores the metadata of the engine, such as the metadata of the
- Cache
- Speed up queries.
Data Model
The data model provided by the storage engine is between the key-value model and the tabular model.
tag-1, ..., tag-m, timestamp -> field-1, ..., field-n
Each row of data contains multiple tag columns, one timestamp column, and multiple field columns.
0 ~ mtag columns- Tag columns can be nullable.
- Specified during table creation using
PRIMARY KEY.
- Must include one timestamp column
- Timestamp column cannot be null.
- Specified during table creation using
TIME INDEX.
0 ~ nfield columns- Field columns can be nullable.
- Data is sorted by tag columns and timestamp column.
Region
Data in the storage engine is stored in regions, which are logical isolated storage units within the engine. Rows within a region must have the same schema, which defines the tag columns, timestamp column, and field columns within the region. The data of tables in the database is stored in one or multiple regions.
Data Layout in SST Files
When a memtable is flushed, Mito writes its rows into immutable Apache Parquet SST files. For the Parquet file format itself and how SST files are indexed, see Data Persistence and Indexing.
Within an SST file, rows are sorted by (primary key, time index). Rows that share the same primary key (the tag columns) belong to the same time-series and are stored contiguously, ordered by timestamp. This locality is what makes scanning a single series cheap and improves compression. For append-only tables without a primary key, rows are sorted by the time index alone.
For example, consider a table that stores host metrics:
CREATE TABLE host_metrics (
host STRING,
region STRING,
ts TIMESTAMP TIME INDEX,
cpu DOUBLE,
memory DOUBLE,
PRIMARY KEY (host, region)
);
Mito groups rows by primary key and orders them by time, so the data within an SST conceptually looks like:
| host | region | ts | cpu | memory |
|---|---|---|---|---|
| host-a | us-east | 10:00 | 0.42 | 7.1 |
| host-a | us-east | 10:01 | 0.47 | 7.4 |
| host-a | us-west | 10:00 | 0.31 | 6.8 |
| host-b | us-east | 10:00 | 0.80 | 8.6 |
Besides the table columns, Mito stores three internal columns in each SST file so it can merge, deduplicate, and apply deletes correctly when reading from multiple memtables and SST files:
__primary_key: the encoded primary key (tags) of the row.__sequence: the sequence number of the row.__op_type: the operation type of the row (put or delete).
Each Parquet SST is split into row groups, the unit that Parquet can read or skip independently. Every row group carries column statistics such as min value, max value, and null count. Mito also records file-level metadata for each SST, including the time range, row count, row-group count, available indexes, and the primary-key range. These statistics drive the scan pruning described below.
Mito supports two SST formats, flat (the default) and primary_key, which encode the primary key differently and are tuned for different primary-key cardinalities. See SST format and the table design guide for how to choose between them.

Scan Pruning
Mito avoids reading data that cannot match a query by combining several pruning steps, from coarse to fine:
- Time-range pruning. Files and memtables whose time range does not intersect the query's time range are skipped before opening any reader. This is usually the cheapest and most effective step for time-series queries.
- Row-group statistics. If a row group's min-max statistics prove that no row can match a predicate, the whole row group is skipped.
- Indexes. Inverted, skipping, and full-text indexes provide more selective pruning for predicates that statistics cannot resolve. See Data Persistence and Indexing.
